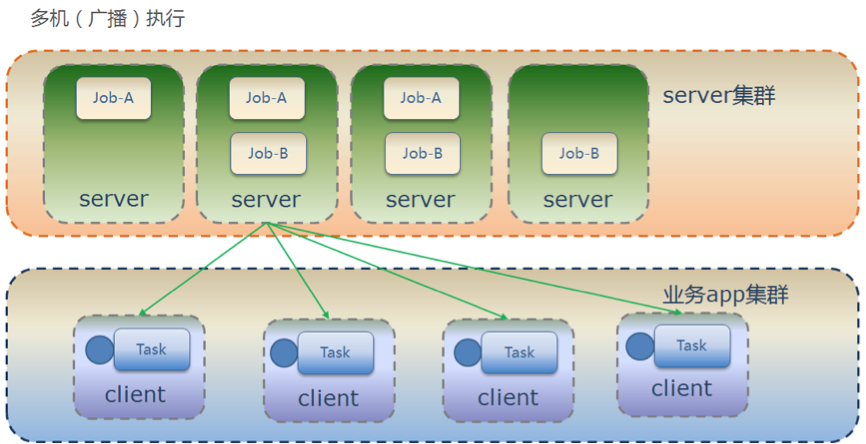
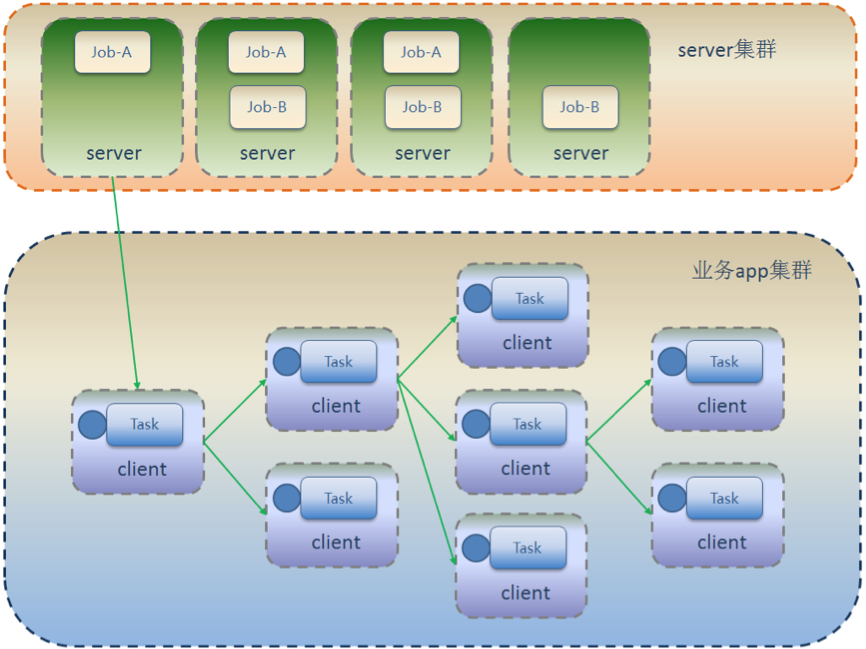
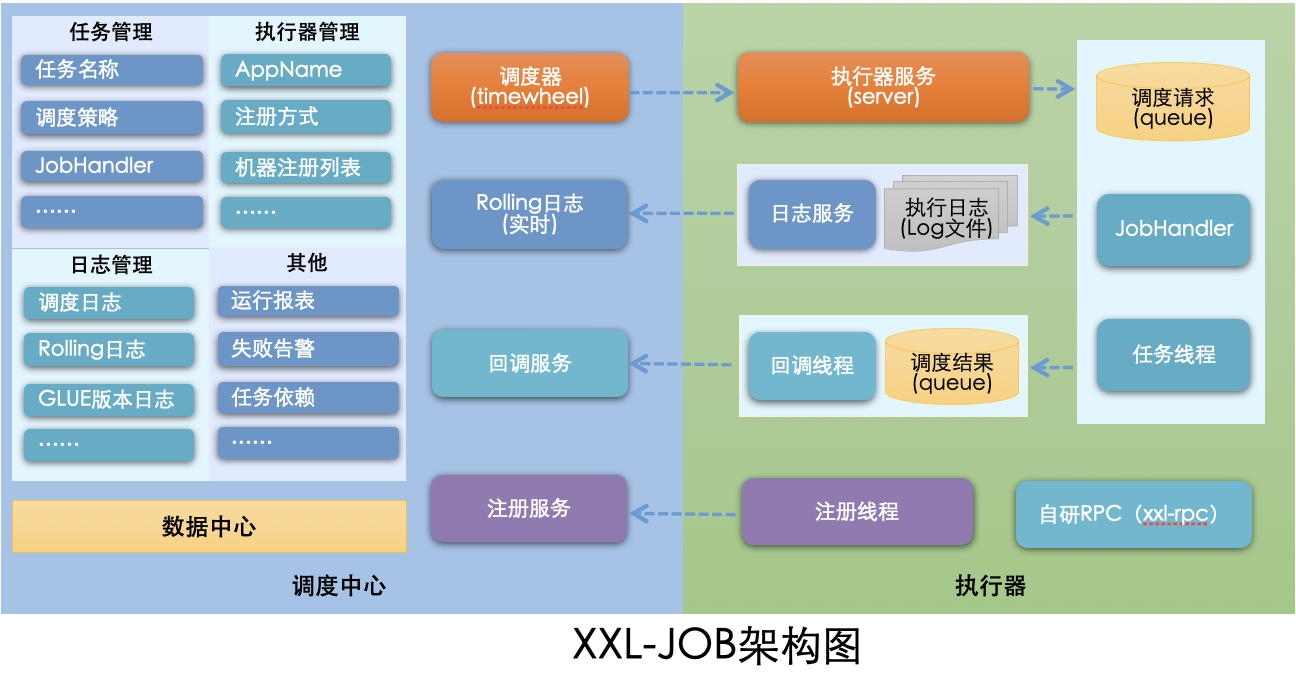
乐观锁&悲观锁
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
再比如Java里面的同步原语synchronized关键字的实现也是悲观锁。
乐观锁
顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。
乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
乐观锁的实现可以通过设置一个version字段,每次更新的时候按照version条件去更新,version不匹配则更新失败